前言
除了在互联网公司工作的那段时间,抱着表格睡觉是站长工作的常态。特别的,为了「合规」和「安全」,现在不少涉及到核心金融业务的机器,都换成了所谓的“银河麒麟”系统。其中,光一个软件适配,就难倒了无数英雄汉(包括但不限于:证书签名/验签适配、国产打印机驱动适配、第三方文件搜索适配)。万幸,或是WPS很早就加入了信创环境的适配中,常用的文字编辑、表格处理需求至少还没遇到除了闪退外的其他问题。但嘴上骂归骂,作为领会不到如何建立Connection的牛马,也只能学习着主动适应这些“宝贝”机器。
不过,本文无心再列长篇指摘信创的种种不足,更多是希望分享下如何在匮乏且版本落后的软件生态、极低的用户权限、隔离的网络连接环境下,挖掘WPS表格具备的功能,尽可能简化日常办公中的数据分析工作。
实务中的堵点与解决思路
快速数据合并
或是因为信息安全,亦或是因为带宽紧张,从某系统A中下载数据时通过前端操作一次性只能下载5000条,但该系统一个月至少会产生15000条数据。通常情况下,需要手工按互不交叉的数据类别(如某数据类别所含数据已超5000,则还需按时间拆分,分为上半月、下半月数据后再处理)将数据表下载到本地后进行合并,筛选清理部分不需要的数据指标后,再对数据展开分析。需密集用数且对时效性要求高时,重复的手工操作容易让人生厌,更容易引入不易察觉的失误。
为此,站长微调了数据处理流程,并基于自身的理解尽可能自动化对表格的操作(以下每一个使用「」括起来的都代表一个独立的Sheet):
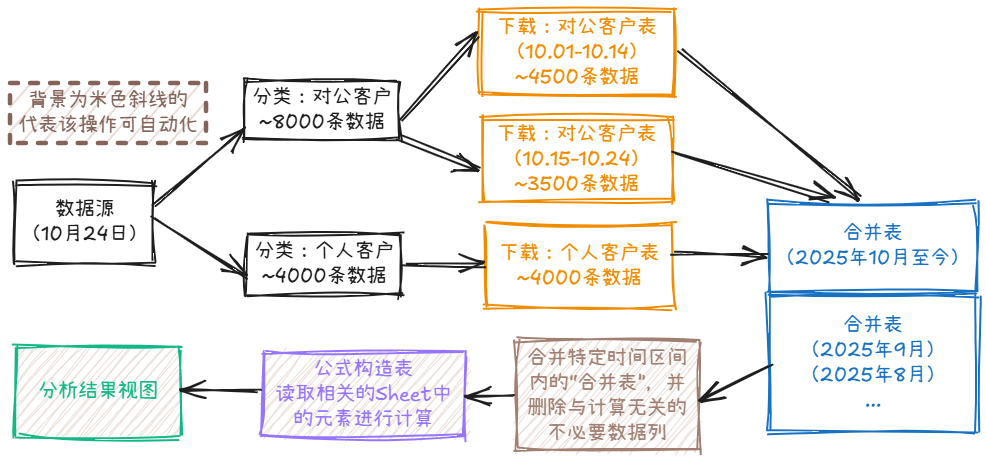
追求解耦合。 不直接在原始数据上进行操作,避免破坏已合并的数据源导致需重新合并。为此,站长设计了一套「原始数据」→「计算所需的数据列」→「公式计算层」→「结果视图」的流程。其中,将「计算所需的数据列」独立存为一个Sheet是为了肉眼查错;将「公式计算层」「结果视图」独立存储,是为了避免对应用过滤器是筛选数据时,影响其他公式的计算结果。
水平分表。 由于站长处理的数据具有明显时序性,因此可以参考数据库设计,基于自然月对数据进行水平分表。其一,避免在合并最近月的数据时,因误操作等原因影响到过去月的数据,导致结果出现异常;其二,以自然月做划分在实务中足够灵活,后续哪怕是使用硬编码的方式编写宏合并指定时间区间的数据都不复杂;其三,针对单个月的数据进行复杂公式计算时,不会因时间复杂度过高而导致计算时间过长(实务中,单月数据15000条,$O(n^2)$时间复杂度跑久一点也是可接受的)。
视图处理。 同样是参考数据库设计,「结果视图」中不存储任何原始数据,仅存储对应数据的引用。一方面,当需要将当前时刻操作得到的「结果视图」保存下来时,可直接复制到新的工作簿中;另一方面,当发现「公式计算层」不完善时,可以实现修复问题后同时修复受影响的所有视图(例外:当引用的数据列被删除时,需重新建立引用)。
由此,站长形成的数据合并及处理架构如下图所示(其中,米色斜线背景代表站长已完成本步骤的自动化):
合并单元格下的定点取数 & 看板设计
为了表示指标间的包含关系,实务中常用到合并单元格。为便于讲述思路,本小节都将围绕下面的示例进行说明:

从人类可读的角度出发,合并单元格只会引入少许多余的列宽和行高的格式微调,不会有什么影响。但从统计的角度来看,通过“值”去匹配对应的行(例如:基于客户姓名匹配对应行)或列(例如:基于指标名称匹配对应列)时,必须匹配合并单元格的左上角才能取到相应值进行比较,这在公式计算上引入了新的堵点。网络上的方案,除利用宏定义一个新的合并单元格取值函数外,多数都是围绕着业务情景给出的方案(例如:当员工的工资位于合并单元格时,额外添加当前员工对应工资取数位置取值为0,则自动沿用上一位员工的工资的规则来完成统计)。
站长本想设计个宏函数一劳永逸,但考虑到兼容性和易用性,还是基于实际需求做了个简易方案。以下为站长日常所处理数据的特征:
合并单元格多是因为表示不同指标间的包含关系,且习惯纵向放主体(匹配行)、横向放指标(匹配列)。
匹配指标时暂时只会用到“精准匹配”,不会用到“模糊搜索”。
不同的指标间名称不会完全相同,且即使在指标名匹配中使用通配符也可以区分不同的指标。
基于以上特征,站长选择结合MATCH和MAX对合并单元格的指标进行过滤。由于MATCH在无任何匹配时将返回N/A,且可通过IFNA自定义出现N/A时的函数返回值,即可以:利用MATCH对每一行执行“指标名称”的匹配(无任何匹配时,返回-1)。最后,取所有MATCH中最大返回值,即为对应指标所在的列数。举例来说,当合并单元格后的某指标占据了第3行到第4行,则公式为:
| |
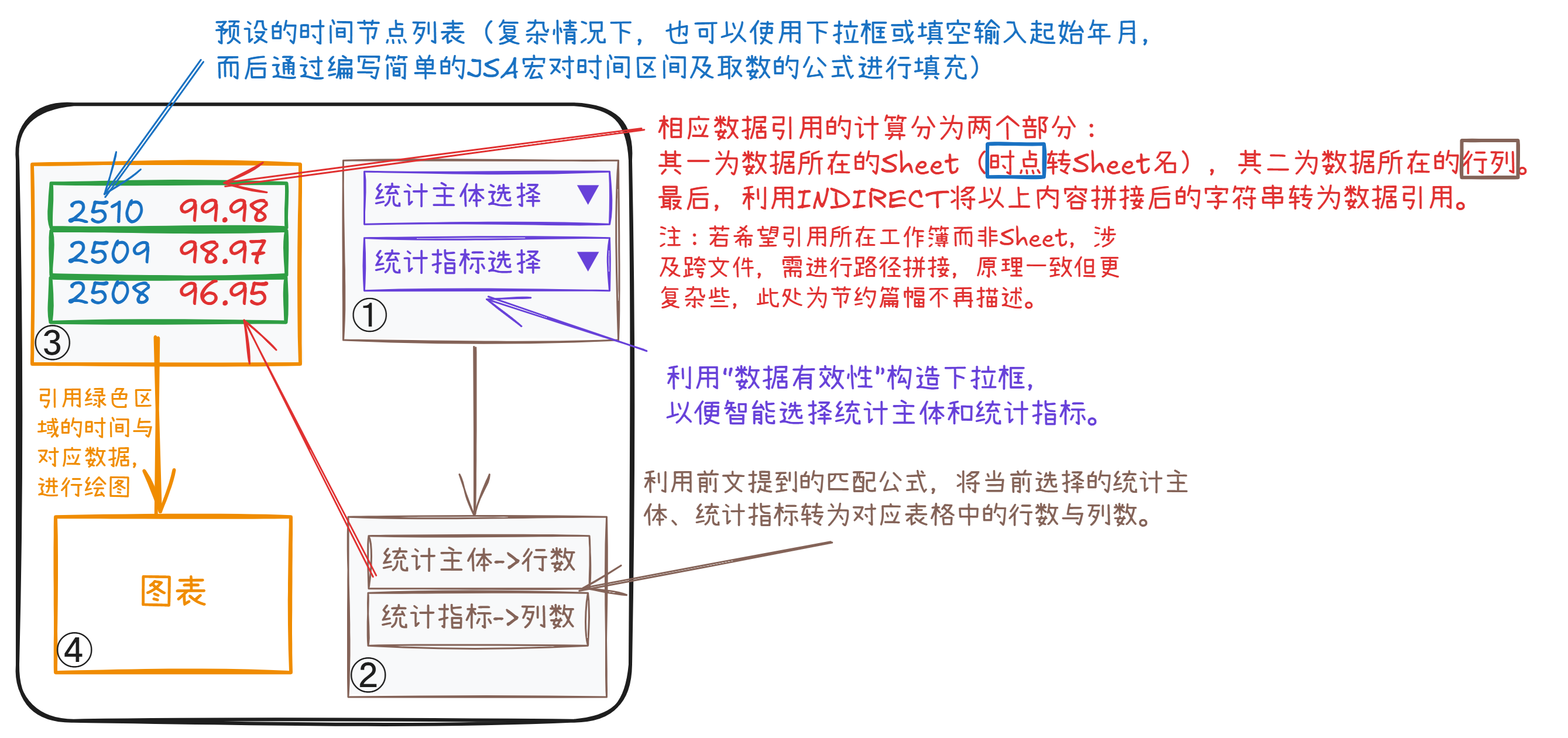
解决匹配问题后,可以使用INDEX等函数将匹配得到的行列数转为形如$A$1这样的绝对坐标,再拼接到INDIRECT中转为引用,实现更灵活地使用数据。站长基于工作需求做过一个简单的图表看板,其流程大致如下:
① 利用“数据有效性”构造下拉框,以便智能选择统计主体和统计指标。
② 利用上方提到的匹配公式,将当前智能选择的统计主体、统计指标转为对应表格中的行数与列数。
③ 利用
INDIRECT函数将预设的时间节点(可转化为存放对应自然月数据的Sheet的名称)与行列数拼接成的字符串转为对数据的引用。复杂需求下,也可使用下拉框或填空等方式输入起始年月,而后通过宏在相应位置填充时间节点及对应的INDIRECT拼接引用公式。④ 引用含时间节点与引用数据的区域进行绘图,以便直观地查看数据的变化情况。
同比、环比值计算及跨时跨表校验
实际工作中,有时需管理统计若干个下属部门/单位报送的多套数据统计表。如缺乏统一的数据收集系统,或落后残旧的系统不支持设定数据计算、校验的公式时,纯靠人工对数据进行校验效果是很局限的,且在需要大量重复操作的情况下,容易让人感到烦躁。
基于以上实际情况,可以列出以下需求:
支持通过设置统计时点、填报源名称等变量,快速打开多个填报源的数据统计表并复制到同一工作簿。
支持通过调整预设的变量占位符、变量映射关系、校验公式,快速对指定的数据统计表进行校验。
基于变量映射关系与预设模板,将含变量占位符的自定义校验公式翻译为自然语言表示的公式,供查错。
由于引入了多个以占位符表示的变量和自定义程度高的校验公式,采用JSA宏设计函数满足以上需求会比较合适。特别的,同一场景下的需求不代表要在同一个函数或工作簿中一次性解决,对每个子需求设计独立的解决方案,或能在未来遇到相似场景时实现快速复用。于是,从实务出发,站长将以上需求拆解为跨工作簿复制Sheet、解析变量并执行公式、将含变量的公式翻译为自然语言3个子需求。
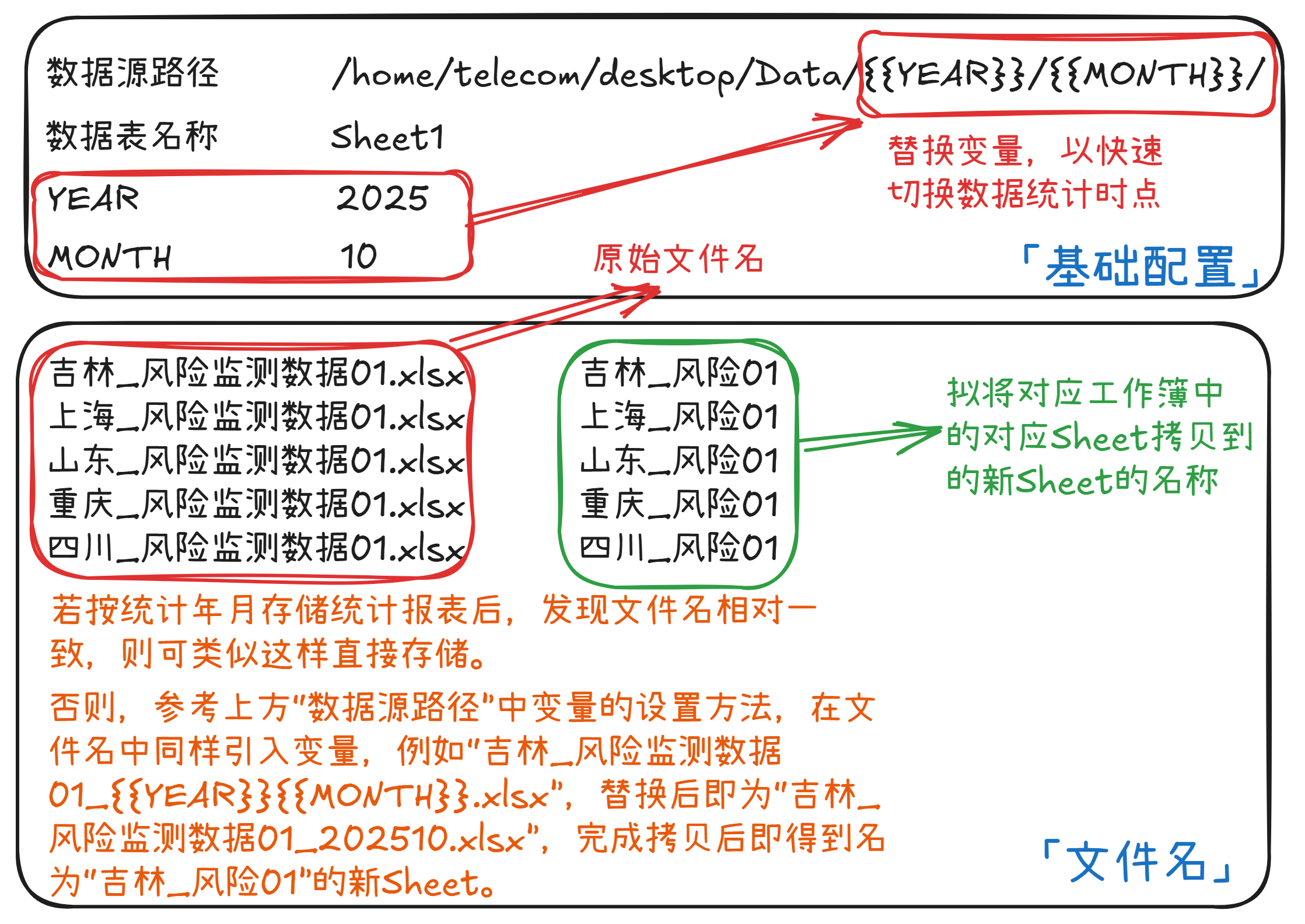
跨工作簿复制Sheet是其中最简单的。只需以合理的方式存储数据表的相关文件信息(例如:文件夹路径、文件名、需复制的Sheet名),调用Application.Workbooks.Open()获取对应的Workbook对象后再根据预设的名称拷贝对应的Sheet对象即可。站长的简版实现方案是创建「基础配置」「文件名」两个Sheet,通过在「基础配置」中设置数据表存放的文件夹路径(可以在路径中适当添加变量,后期在JSA函数中使用正则进行替换,以适配更灵活的使用场景)、需复制的Sheet名,而后在「文件名」中复制粘贴在数据表存放目录下执行ls命令的结果即可。为了更简化操作,还可以画个按钮并将入口函数绑定到按钮上,以后在调整参数后点击即可基于最新配置跨工作簿复制对应的Sheet。
解析变量并执行公式的实现难度取决于具体设计。
首先,为了简化访问数据的难度,站长利用“跨工作簿复制Sheet”的方案将所有涉及到的Sheet以
而后,将以上格式使用变量替代,即可用
{{Time|Time_MoM|Time_YoY}}代表统计时间,其中:Time、Time_MoM、Time_YoY分别表示当前、月度环比与年度环比;{{Source}}代表数据来源,例如吉林、上海、山东,而后通过枚举并替换需要校验的数据来源来实现一条校验规则表达式自动应用到多份数据来源中;{{TableCode}}代表数据表模板编号,此时(统计时间, 数据来源, 数据表模板编号)组成的键唯一,保证同一工作簿中的Sheet名称两两间不重复。
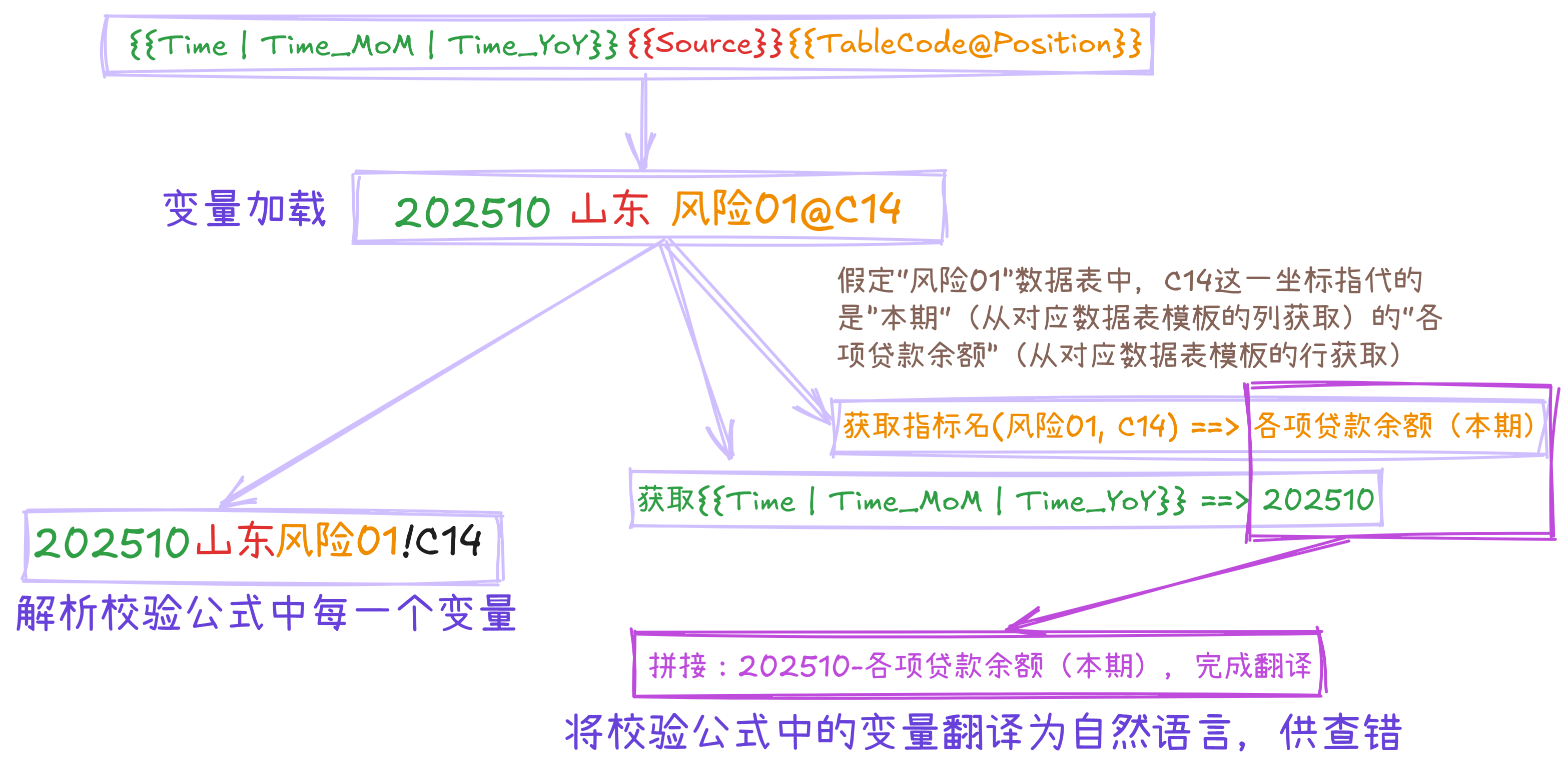
最后,需要为以上表示方法添加对具体单元格的引用。此处先给出一个更直观的方案:由于在上面的设计方案下,Sheet名很容易由变量拼接出来,因此可以直接将所需援引的坐标拼接到变量表达方式的最后,即:{{Time|Time_MoM|Time_YoY}}-{{Source}}-{{TableCode}}!{{Position}}。
例如,当我的校验规则需要解析【2025年10月末】由【山东省分公司】填报的【风险监测表01】中的【C14】单元格时,可以将{{Time}}设置为【202510】,将{{Source}}设为【山东】,将{{TableCode}}解析为【风险01】,并将位置{{Position}}写入其中,此时变量表达为{{Time}}-{{Source}}-{{TableCode}}!C14,完成解析后原变量表达将变为202510-山东-风险01!C14,不论是用在Indirect内置函数中,还是用JSA的Application.Evaluate直接执行公式,都是很方便的。
自然语言翻译的核心在于提取数据表模板编号{{TableCode}}和单元格位置{{Position}}。
如果使用上文描述的【更直观的方案】,来尝试满足需求【基于变量映射关系与预设模板,将含变量占位符的自定义校验公式翻译为自然语言表示的公式,供查错】,站长尝试了下,需构造较为复杂的正则表达式或字符串匹配规则获取{{TableCode}}、{{Position}},才能获取翻译所需的指标名称。
因此,站长将先前的变量表达方式再次进行了微调:{{Time|Time_MoM|Time_YoY}}-{{Source}}-{{TableCode@Position}}。微调后的表达方式天然将数据表模板编号{{TableCode}}和单元格坐标{{Position}}关联在一起,且通过@这一特殊的分隔符隔开,以降低正则表达式的复杂度。
最后,只需要先完整匹配整个变量表达方式{{Time|Time_MoM|Time_YoY}}-{{Source}}-{{TableCode@Position}},而后分别提取{{Time|Time_MoM|Time_YoY}}和{{TableCode@Position}}并解析对应的值,最后将其拼接并替换整个变量表达方式,即完成了整个翻译解析的过程。
假定当前统计时间为202510,数据源包括吉林、上海、山东,且风险01数据表模板中,C14代表的是各项贷款余额(本期),设计规则“各项贷款余额”月度环比增长5%以下示例如下:
设计目标:月度环比各项贷款余额增长应小于等于5%;
校验规则:
{{Time}}-{{Source}}-{{风险01@C14}}/{{Time_MoM}}-{{Source}}-{{风险01@C14}}<=105%变量解析后得到的公式(吉林):
202510-吉林-风险01!C14/202509-吉林-风险01!C14<=105%变量解析后得到的公式(上海):
202510-上海-风险01!C14/202509-上海-风险01!C14<=105%变量解析后得到的公式(山东):
202510-山东-风险01!C14/202509-山东-风险01!C14<=105%
自然语言翻译(吉林为例):
202510-各项贷款余额(本期)/202509-各项贷款余额(本期)<= 105%
由此,我们即得到一套可以编写简易校验规则的系统,并通过实现简易翻译便于查错以及推广使用。
未来改进思路
以上解决思路,都是聚焦于具体业务的解决方案。为进一步提高通用性和实用性,站长在这里分享下未来希望改进的方向,同时供各位读者参考:
需跨工作簿引用时,能根据文件路径信息自动前台/后台打开对应文件,并能探测文件是否已被正常打开。
抽象数据处理中通用步骤并模块化,并参考“数据中台”的设计实现丐版兼容层,实现数据处理的自由组合。
独立“配置表”,以存储数据处理中工作簿路径等常用数据,并支持用指标匹配函数自动配置数据有效性约束。
设计常见数据统计场景(例:贡献率、占比)的计算模板,并允许通过宏调用模板一键搭建数据视图。
独立设计“指标异动规则表”以自动校验对应Sheet的数据(例:视图层是否成功取数;指标是否超限制)。
尝试引入“因果推断”系列的相关统计框架,以便尽可能剔除部分变量的影响和发掘变量之间的隐性关系。
结语
可能最后,有的读者会问:为什么不用Python?
因为没有哇 (ˉ▽ˉ;)
而且,用Python主要用的是丰富的第三方库,在高定制化的环境中,效果可能不会有想象中那么好。除此之外,就只是把表格数据读到了别的数据结构中,便于操作而已。站长认为,数据结构间的差异,并没有那么大。复杂程度,主要还是聚焦于业务本身。站长在这里给出两个实际业务中遇到的场景,以及站长的解决思路,也是希望起到一个抛砖引玉的作用(•ェ•*)
最后,再简单水几句。
冷,最近真冷啊!!这冷空气真打了人一个措手不及,听说有些地方的候鸟都再也飞不起来了。
前段时间买的车因为天气显得更可靠了,这里再附一段最近在车上放的歌,赠予各位读者:
莫再悲 莫再伤
遇到悲哀休夸张
谁亦要经风与浪
谁遇挫败不受伤
逝去的 莫再想
路正崎岖更漫长
何用叹息风里望
宝贵光阴笑着量
——《莫再悲》,林子祥